| Cascade DataHub™ : Version 6.4 | ||
|---|---|---|
 | Chapter 7. Data Logging |  |
| Cascade DataHub™ : Version 6.4 | ||
|---|---|---|
| | Chapter 7. Data Logging | |
Table of Contents
The Cascade DataHub can log data to any ODBC compliant database or text file[1].

With this feature of the DataHub you can:
Log data to any ODBC-compliant database, such as MS Access, MS SQL Server, MySQL, Oracle, and many more
Log to existing database tables, or create new tables as necessary.
Log data to an ODBC database (or soon, text file) from any other data source connected to the DataHub.
![[Note]](images/note.gif) | To write data from a database into the Cascade DataHub, please refer to Tutorial 3: Writing data from a database to the DataHub in the DataHub ODBC Scripting manual. |
The Cascade DataHub's ODBC Data Logging interface provides an easy way to connect to a DSN, create or select a table, assign data point properties to table columns, and assign a trigger and conditions for logging points. The fastest way to learn how to use the interface is by watching the web-site video or by using the Quick Start.
In general, a database is a collection of information. Computerized databases store data in tables, which are accessed through a database management system or DBMS, such as SQL Server, MS Access, MySQL, Oracle, etc. All of these are capable of storing data in related, linked tables, which taken together are called a relational database. Most modern computerized databases are relational databases.
A database table is a logical grouping of related data, organized by the common attributes or characteristics of individual data items. Each column or field in the table contains a particular attribute, and is of one particular data type. Typical data types include boolean, string, numeric, date/time, etc. Each row or record in the table contains a complete set of every data value related to a single item.
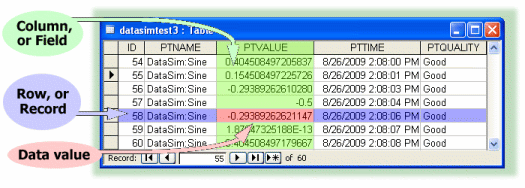
For example, a table containing data from the Cascade DataHub might have columns (fields) for a point name, value, timestamp, and quality. Each row (record) would show the various data values logged for that point at different times:
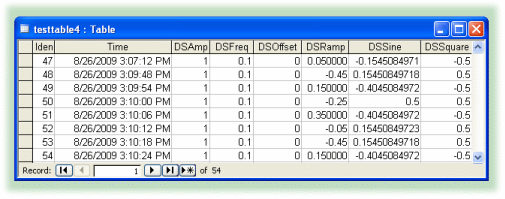
A different kind of table might have one column for a timestamp, and then additional columns containing the values of different DataHub points logged at each time, like this:
A database table may require each row (or record) to be uniquely identified. This is commonly done through a key column, whose main and (sometimes only) purpose is to provide a unique identifying value to the row. Most DBMSs allow this value to be assigned manually by the database user, or automatically through an auto-incrementing counter or other mechanism. It is possible for a table to have multiple key columns, but some funtions in the Cascade DataHub will only write to tables with a single key column. For more information about configuring database tables with the Cascade DataHub, please refer to Section 7.4, “Configuring a Database Table”
Connecting to a database is done through the DBMS, which normally offers two possibilities: native drivers and ODBC (Open Database Connectivity). Native drivers are inconvenient to use because each requires its own programming interface. ODBC, on the other hand, specifies a standardized, common interface that is available from almost every database vendor, including SQL Server, MS Access, MySQL, Oracle, and many, many more. The Cascade DataHub uses ODBC to connect to databases.
ODBC supports communication with a DBMS locally or across a network, using an ODBC driver. Every ODBC-compliant DBMS provides an ODBC driver, which needs to be installed on the user's machine. For example, there is an ODBC driver for MS Access, for SQL Server, for MySQL, and so on.

You can use the Windows ODBC Data Source Administrator to configure a connection between the ODBC driver and the specific database you want to work with. That configuration is called the Data Source Name, or DSN. For example, the Cascade DataHub references the DSN and uses the configured connection for the ODBC driver to connect to the database.
Configuring the DSN is straightforward, varying slightly depending on the ODBC driver you are working with. Usually you need to select an ODBC driver, create a name for the DSN, and select a database. Other information, such as a login name or password may be required or optional. For more information, please refer to Section 7.3, “Setting up the DSN (Data Source Name)”
Once connected to a database, any queries (requests) to retrieve, modify, add, or delete data must be made through a language. The most popular database query language is SQL (Structured Query Language), pronounced "sequel" or "ess-kyu-el". Created in the 1960s, this language has become a widely-used standard supported by most DBMSs, although there are some minor variations in certain commands offered.
The Cascade DataHub uses SQL to write to and read from databases. When you configure the Data Logging interface to write DataHub point values, under the hood the commands used are written in SQL. The DataHub scripts also use SQL commands to write and read data. For example, the following line from the ODBCTutorial3.g script uses an SQL SELECT command to pull all of the data from a database table.
result = .conn.QueryToClass (.tableclass, string ("select * from ", .tablename));The SELECT command is often used with the FROM and WHERE operators, in queries such as this:
SELECT data_element_1 FROM table_1 WHERE data_element_1 > 32 and data_element_1 < 212;
The syntax of SQL is fairly simple, and there are many books and online tutorials that can help you learn. The information presented here about SQL, ODBC, and databases in general should be enough to get started logging data with the Cascade DataHub.
[1] Text logging will soon be available in the Data Logging interface, but can now be configured through DataHub scripting.
| |  | |
| 6.9. How to Send SSL-encrypted Email |  | 7.2. Quick Start |
Copyright © 1995-2010 by Cogent Real-Time Systems, Inc. All rights reserved.